
CLIP : Learning Transferable Visual Models From Natural Language Supervision
2021년 등장한 CLIP은 VL(Vision language) pretraining 분야의 새로운 패러다임을 열었습니다. 기존의 고정된 class label(cat, dog 등)을 활용한 supervised learning은 이미지의 semantic 정보를 제대로 추출해내지 못한다는 한계가 존재했는데요. 충분히 성능 좋은 image, text encoder가 있음에도 불구하고, 필요한 정보들을 얻지 못한다는 것은 다양한 downstream tasks(Image retrieval, Image captioning, VQA 등..)에 적용하기 매우 힘들다는 것을 의미합니다.
3줄 요약
- Large noisy web data(WIT) 구축 -> 기존의 NLP LLMs들이 주로 사용하던 대용량 데이터 셋을 활용한 representation learning 방법을 적용
- Text embedding과 Image embedding을 연결하는 새로운 방법을 제시함으로써, Crossmodality의 가능성 제시
- Zero-shot 성능 대폭 향상
Abstract & Introduction
CLIP은 위의 한계를 극복하기 위해 기존의 딱딱한 class label 기반 학습에서 벗어나, 보다 자유롭고 다양한 raw text data를 활용하고자 했습니다. 엄청난 크기의 dataset을 활용하는 LLMs(Large Language Models, like GPT)에서 아이디어를 차용하여, 많은 양의 raw text data를 supervision으로 제공하고자 했는데요. 4억개 가량의 raw (image, text) pair를 효과적으로 활용하기 위해서 Contrastive Learning 기법을 사용합니다.
결과적으로 거대한 dataset으로부터 다양한 semantic 정보를 학습하고, 학습된 정보들을 서로 연결해주는 방법을 제시함으로써, gold-label을 활용한 supervised learning의 성능을 뛰어넘을 수 있었습니다.
Main Method
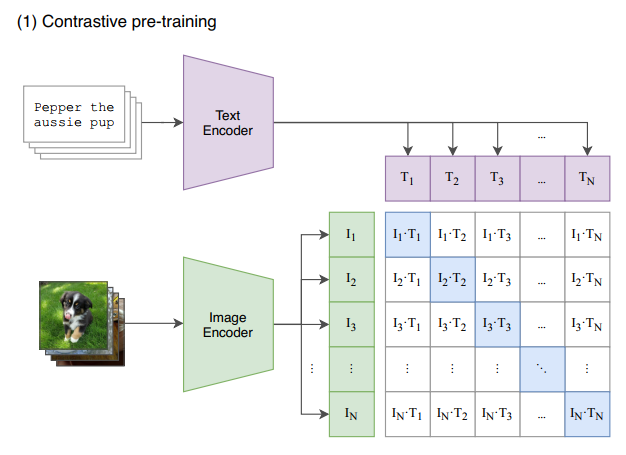

CLIP은 학습 과정에서 2개의 encoder를 사용합니다.
먼저 image, text encoder가 각 데이터를 인코딩하면 그들은 projection을 통해 같은 공간 상에 놓여지는데요.
그 후, 같은 공간에 놓여진 embedding vector끼리 contrastive learning을 진행하게 됩니다. positive pair끼리의 코사인 유사도(cosine similarity)는 최대화하고, negative pair끼리의 유사도는 최소화합니다.
최종적으로, CE(Cross Entropy) Loss를 활용하여 Cross-modality를 학습하게 됩니다.
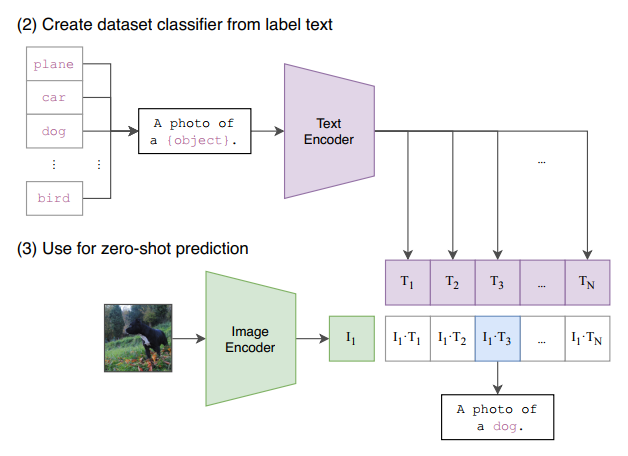
일반적으로 Image classification task의 class는 단일 라벨로 구성되어 있지만, CLIP의 text data는 짧은 문장으로 구성되어 있습니다. 단일 라벨의 경우, 충분한 semantic 정보를 포함하지 못 할 뿐만 아니라 다의성을 가질 문제도 존재하기 때문에 약간의 수정을 거쳐 text encoder에 삽입하게 됩니다. image encoder를 거쳐서 나온 feature는 text encoder의 결과들과 우유사도 계산을 하게 되고, 최종적으로 가장 유사도가 높은 클래스를 정답으로 반환하게 됩니다.
이와 같이 text prompt의 문장 형식을 조정하는 것을 'Prompt Engineering'이라고 부릅니다. Prompt Engineering은 모델의 성능에 상당한 영향을 끼치므로, prompt를 잘 선택하는 것이 중요합니다.
Results
CLIP은 다양한 연구들을 통해 그 성능을 입증해냈습니다.


먼저, Image classification task에 대한 zero-shot 성능과 prompt engineering의 효과입니다. 3가지의 데이터 셋에 대해서, 기존에 비해 놀라운 Zero-shot 성능 향상을 보이네요.
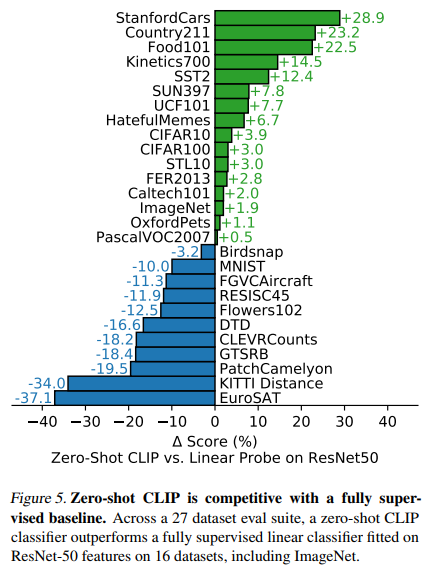
왼쪽은 Fully supervised, 오른쪽은 few-show methods와 Zero-shot CLIP을 비교한 그림입니다. 몇몇 데이터 셋에 대해서는, 아직 fully supervised method가 우세한데요. EuroSAT과 같이, fine grained detail을 잡아내는 능력이 필요한 데이터 셋에 대해서는 아직 성능이 부족한 것처럼 보입니다. few-shot methods 보다는 확실히 더 좋은 성능을 보이네요. 그래도 fully supervised methods와 Zero-shot CLIP의 성능이 비슷한 것이 굉장히 인상적입니다.
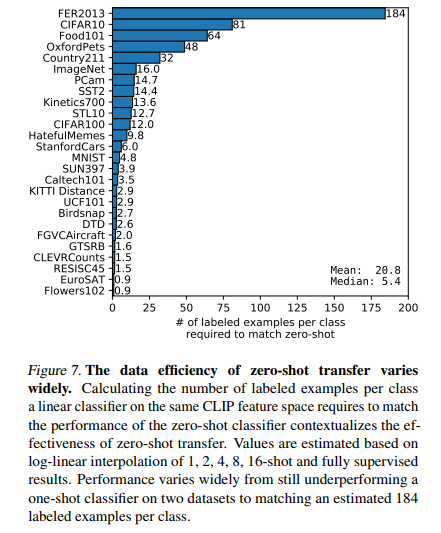

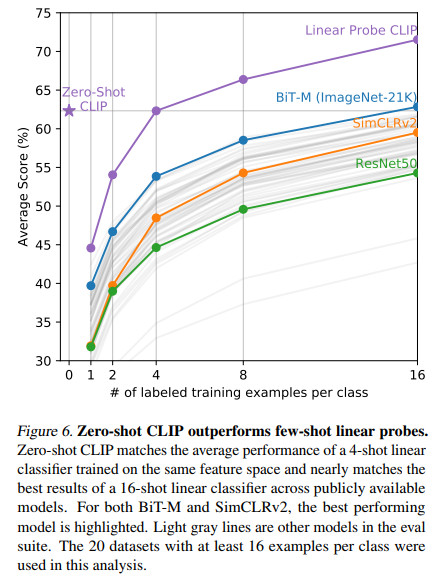
왼쪽 사진은 logistic regression classifier가 몇 개의 example을 학습하면 Zero-shot CLIP을 따라잡을 수 있을까를 나타낸 그림입니다. 오른쪽 사진의 linear probe 성능과 Zero-shot 성능을 비교한 사진입니다. y=x 그래프는 이상적인 Zero-shot classifier 성능을 나타낸 것인데요. 대부분의 데이터 셋에 대해서, 아직은 Zero-shot 성능이 fully-supervised classifiers보다 성능이 좋지 않게 나오는 것을 확인할 수 있습다.
위에서 zero-shot transfer 성능에 대해 알아봤다면, 이제는 Representation Learning 성능을 알아보겠습니다. Downstream tasks에 적용하기 위해서는, 결국 image feature를 잘 뽑는 것이 중요한데요.

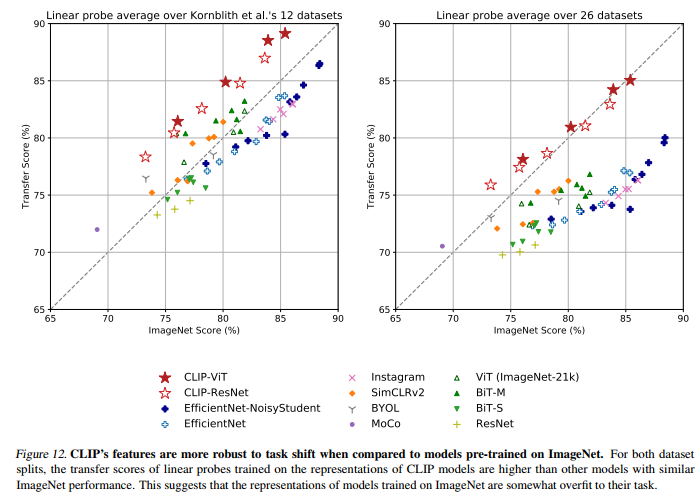
성능 평가는 각 모델로 뽑은 feature들을 선형 모델에 넣은 결과로 비교하였습니다. 기존의 SOTA 모델에 밀리지 않고, 좋은 성능을 보입니다. 또한, 다른 task로 transfer해도 좋은 성능이 나옵니다.
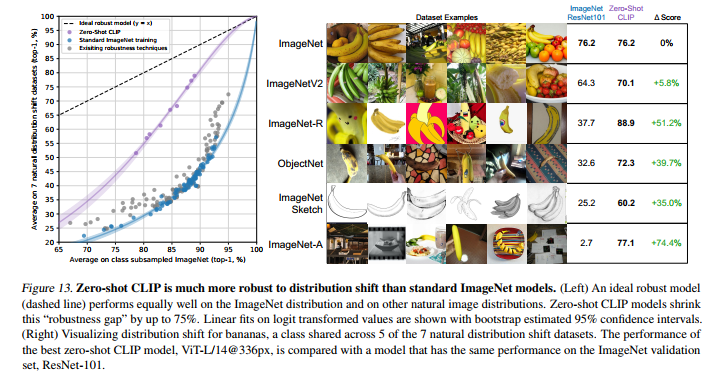
이 뿐만 아니라, data distribution shift에도 robust한 모습을 보입니다.
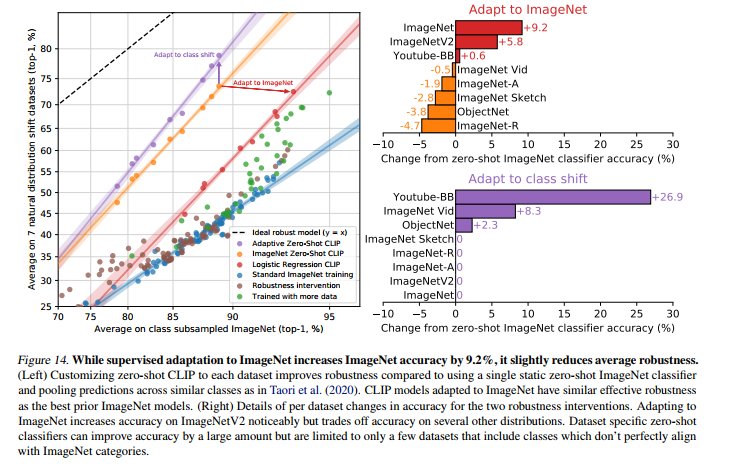

위 사진들은 trade-off들을 나타냈습니다. 왼쪽은 Robustness-Accuracy trade-off로 ImageNet data로 'adapt' 할수록 정확도는 높아지지만, robustness는 떨어지는 걸 확인할 수 있습니다. 오른쪽 사진도 비슷하게, shot이 늘어날수록 해당 task에 대한 성능은 높아지지만 모델의 generality가 감소하는 걸 볼 수 있네요.
이외에도, CLIP과 사람을 비교해봤는데...월등히 뛰어나다고 합니다. 신기하네요..

LLMs을 사용했기 때문에, LLM의 근본적인 한계점인 bias 문제가 존재합니다. 예를 들면, 남자나 여자의 직업에 대한 편향을 들 수 있겠네요.
Conclusion
Game changer라고 불릴 만큼, 정말 다양한 가능성을 제시해준 논문이며 정말 많은 ablation study를 통해 논문의 성능을 입증했다는 점에서 꼭 읽어봐야 하는 논문이라 생각됩니다. CLIP을 기반으로 한 다양한 후속 연구들을 살펴보는 재미가 있을 것 같네요.
'논문 리뷰' 카테고리의 다른 글
| 📹빠르게 보는 BLIPv2 논문 리뷰📹 (0) | 2023.03.05 |
|---|---|
| 📹빠르게 보는 BLIP 논문 리뷰📹 (0) | 2023.03.04 |