
BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
NLP 분야에서 유행하는 LLM(Large Language Model)의 성능은 이미 다양한 연구들로 충분히 입증되었습니다. 최근 각광받고 있는 ChatGPT 역시 GPT-3.5라는 LLM 모델을 기반으로 하는데요. Multimodal 분야에서도 Large web dataset으로 학습하는 방법론이 증가하면서, LLM과 미리 학습된 Image encoder를 함께 사용하고자하는 시도가 계속되어 왔습니다.
다만 LLM은 학습 과정에서 이미지 정보를 전혀 받지 못했기에, LLM에 이미지 정보를 전달해줘서 image, text 데이터를 align 해주는 단계가 꼭 선행되어야 합니다. 오늘 소개할 BLIPv2는 frozen image encoder과 LLM 모델을 연결해주는 새로운 방법(Q-former)를 제시합니다. frozen된 모델들을 가져옴으로써 파라미터 효율도 좋을 뿐만 아니라, 거대 모델의 성능 좋은 representation learning까지 활용해 다양한 VL task의 SOTA에 등극했습니다.
2줄 요약
1. Encoder에 frozen Pretrained Model을 도입하고, 그로 인한 Modality gap은 Q-former를 통해 해결
2. 다양한 VL task에서 SOTA에 등극했으며, 상당한 Zero-shot 성능을 보여줌 -> Multimodal 챗봇의 가능성을 제시.
Abstract & Introduction

BLIPv2는 2가지 단계를 거쳐 학습을 진행합니다. 먼저 Frozen pretrained image encoder를 통해 representation을 얻고, 이미지의 representation을 Q-Former를 활용하여 Frozen LLM에 넘겨줍니다. LLM은 이 정보를 활용하여 VL generative learning을 하는 것이죠.
Q-Former는 간단한 transformer 구조로, frozen image encoder에서 정보를 뽑아내는데 활용됩니다. 첫 번째 단계에서는 이미지로부터 text와 연관된 정보를 뽑도록 학습되고, 두 번째 단계에서는 뽑아낸 정보들이 LLM에 의해 해석가능하도록 훈련됩니다. 결과적으로 Frozen Large Model들로 인한 파라미터 효율성을 얻음과 동시에, LLM의 zero-shot 성능을 VL task에 활용할 수 있게 됐습니다.
Main Method
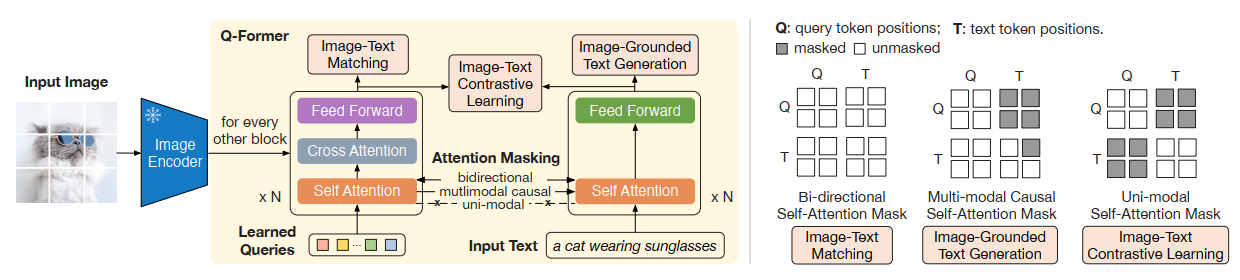
Q-Former는 BLIP에서 사용했던 3가지 목적함수를 활용합니다.
stage 1: ITC(Image-Text Contrastive Learning)
Image representation, text representation을 align하기 위한 목적 함수입니다. 즉, Modality gap을 좁히기 위해 사용되는데요. image transformer에서 나온 query output과 text transformer에서 나온 output간의 pairwise 유사도를 계산하고, 가장 값이 높은 pair를 query-text pair로 선정합니다.
이 때, image와 text가 서로의 정보를 참고하면 cheating이 되기 때문에 이를 막고자 Uni-modal Self-Attention Mask를 사용합니다.
stage 1: ITG(Image-grounded Text Generation)
주어진 image에 맞는 text를 생성하도록 하는 과정입니다. Encoder에서 뽑아낸 이미지 정보는 공유된 self-attention layer를 통해 text tokens로 전해지는데요. 이 과정을 통해, query는 text와 관련된 이미지 정보들을 뽑도록 학습됩니다.
query가 text 정보를 미리 보면 부정행위기 때문에 Multi-modal Causal Self-Attention Mask를 활용하여 query가 text 정보를 참고하지 못하도록 합니다. 또한, text generation task에서 현 시점 이전의 text만 참고할 수 있도록 Self-attention mask를 설계합니다.
stage 1: ITM(Image-Text Matching)
Image와 text의 fine-grained alignment를 학습합니다. image와 text pair가 서로 match 되는지 확인하기 위해 이진분류를 활용합니다.
가지고 있는 모든 정보를 참고해도 문제가 없기 때문에, Bi-directional Self-Attention Mask를 사용합니다.

2단계는 Q-Former를 LLM에 연결하는 과정입니다.
stage 2:
Q-Former의 output query는 완전연결 계층(Fully Connected Layer)를 통해 LLM로 전달됩니다. 완전연결 계층은 output query의 차원을 LLM의 text embedding 차원으로 사영(project)하는 역할을 합니다. 사영된 결과물은 LLM의 text embedding 앞에 붙어 'soft visual prompt'로 활용됩니다.
본 논문에서는 Decoder-based, Encoder-Decoder based 방식을 모두 실험하였습니다. Encoder-Decoder based 네트워크의 경우에는 text를 prefix, suffix text로 나눠 사용합니다.
Pretraining & Experiments & Results
Pretraining dataset은 BLIP에서 사용한 데이터를 그대로 사용했습니다(CapFilt 사용). Pretrained Encoder는 ViT 계열(ViT-L/14, ViT-G/14), LLM으로는 OPT, Flant5 계열 등을 활용했습니다.

기존 모델들보다 파라미터 수는 훨씬 작지만, 더 뛰어난 zero-shot 성능을 보입니다.

역시 강력한 image encoder, LLM을 사용하니 성능이 더 좋게 나오네요.

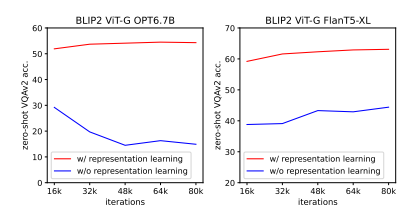
representation learning의 중요성을 알려주는 그림입니다. BLIPv2 이전에 존재하는 모델들은 representation 정보를 주지 않고, image-to-text loss만을 활용해서 modality gap을 해결하고자 했는데요. 위의 실험 결과를 통해, Q-former를 활용한 visual representation 전달 방식이 유의미했다는 것을 알 수 있습니다.
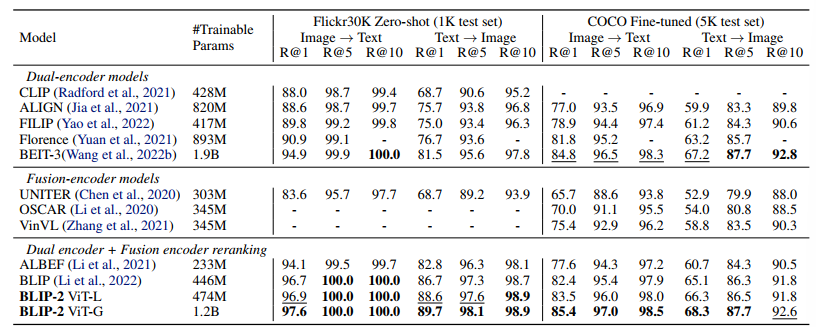
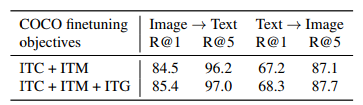
ITG loss를 설계할 때 계획했던 것처럼, ITG loss가 Image-text retrieval 성능 향상에 도움을 줄 수 있다는 걸 확인할 수 있습니다.
Limitations & Conclusion
BLIPv2는 아직 완벽하지 않습니다. Zero-shot 성능이 향상되긴 했지만, 실제 사용할 정도로 좋지는 못하며 특히 in-context VQA exmaples에 대한 성능이 안 좋습니다. 논문 저자들은 image-text pair가 하나라서 이런 문제점이 발생한다고 설명합니다. 어떤 장면을 표현할 때는, 다양한 맥락에서 해석할 수 있기 때문에 image 하나당 여러 text pair가 있는 데이터 셋 활용이 필요하다는 것이죠. 또한 LLM의 특성상 모델 자체가 인간에 의해 편향되는 문제점도 여전히 존재합니다.
그래도 Frozen model간의 modality gap을 메우기 위한 새로운 방법을 제시하고, 여러 VL task에서 성능을 끌어올린 것만으로도 충분히 읽어볼 만한 논문인 것 같습니다. BLIPv2 논문 리뷰는 여기서 마치고 다음에 더 재밌는 논문으로 돌아오겠습니다:) 읽어주셔서 감사합니다.
'논문 리뷰' 카테고리의 다른 글
| 📹빠르게 보는 BLIP 논문 리뷰📹 (0) | 2023.03.04 |
|---|---|
| 📎빠르게 보는 CLIP 논문 리뷰📎 (0) | 2023.03.01 |